今天开始学习Databases Systems CMU 15-445/645/ Fall 2019,课程比较硬核,重点主要集中在怎么样设计一个数据库系统,希望能坚持学完。第一课主要是课程介绍以及介绍一些关于数据库管理系统的基础概念,包括关系模型,以及关于retional algebra 关系代数的一些基本操作。
课程介绍
-
课程主要集中在以下几个方面:
- Relational Databases
- Storage
- Execution
- Concurrency Control
- Recovery
- Distributed Databases
- Potpourri (集合)
-
教材
主要参考 Database System Concepts (第七版) 以及课程笔记。
-
Project
本课将会从零开始实现一个存储管理器,用的语言是C++17。项目将基于一个教学用数据库管理系统BusTub,该系统的大致架构为:
- Disk-Oriented Storage
- Volcano-style Query Processing
- Pluggable APIs
- Currently does not support SQL
数据库管理系统
例子
假设我们现在需要一个音乐商店(类似iTunes)来管理所有的歌手和专辑,那么我们需要存储的信息包括:歌手信息和歌手发布的专辑信息。最简单的思路是将数据库以CSV文件的方式来存储,具体实现方式可以是这样:
-
用一个单独的文件来存储每个我们需要的信息(在这个例子里面就是歌手信息和专辑信息)
-
每次应用想读取信息可以通过解析这些文件来获取

当我们想找Ice Cube的信息的时候,我们可以通过下面的Python来实现
for line in file:
record = parse(line)
if "Ice Cube" == record[0]:
print int(record[1])
但是这种简单的实现方式会遇到很多问题:
- 怎么保证在每个专辑项的时候都保证歌手名字格式是一致的?
- 假如某个人不小心在输入年份的时候输入了一个不合法的string导致没办法转成整数怎么办?
- 当一个专辑有多个创作者是怎么办?
除此之外还有很多实现上的细节需要注意:
- 怎么找到一条特定记录?通过上面的for-loop方法在数据量很大的时候效率会变得很低
- 怎么保证这样的数据库系统可以兼容多平台(手机、平板、电脑)或者多种编程语言?
- 当两个线程想同时向一个文件写入时怎么保证不会互相覆盖?
另外还考虑数据库的安全问题:
- 当程序在往数据库写入记录的时候数据库突然崩溃了怎么办?
- 如果我们向复制数据库在多台机器以保证高可用性的时候需要注意什么?
基于上面提到的问题,我们需要实现一个通用的数据库管理系统(Database Management System)来对数据库进行信息的存储和分析,这个系统需要能做到允许用户自定义,创建,写入查找,更新,管理一个数据库
数据库系统模型介绍
-
Relational Model (关系模型)
早期的数据库系统很难构建和维护,用户在构建系统之前需要清楚知道以后他会怎么使用,软件使用和硬件实现方式耦合度很高,直到1970 年 Ted Codd 提出了一个数据库的抽象概念来避免这种情况,这个模型主要包括以下三个要点:
- 将数据库以关系 (relation) 的方式存在一个简单的数据结构里面
- 数据将会通过高级语言来进行访问
- 物理存储方式留给第三方具体实现(抽象本身不包括实现方式,用户不需要自己实现)
-
Data models & Schema
这里提出了两个概念:
- data model:有关怎么描述数据在数据库里面里面的一系列描述方式
- schema:针对一种特定数据模型给出的对该类型数据的描述方式(这一部分其实不太清楚,看看后续有没有具体的例子)
总的来说,数据模型抽象的概括了我们怎么样存储数据,schema则是说明了具体存了哪些内容
-
一些常见的data model
- Relational:绝大部分的DBMS都是用这个模型,这门课也是学习这种模型
- Key/Value:这个包括下面直到Column-family都是属于NoSql的模型
- Graph
- Document
- Column-family
- Array/Matrix:机器学习里面常用这种模型
- Hierarchical:最后两种比较少见
- Network
-
Relational Model
Relational Model主要包括以下三个要素:
- Structure(结构):有关关系和他们的具体内容的定义(描述)
- Integrity(完整性):保证数据库的内容符合相关约束条件(给定一个数据库怎么判断他是不是符合标准)
- Manipulation(操作):怎么访问和更改数据库的内容
音乐商店例子:数据库描述
根据这三个要素,再回头看最初提到的音乐商店的例子:
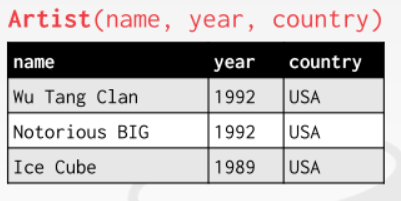
在这个例子里面,relation(关系)指的就是所有描述一个记录的无序集合 (unordered set),这里每一行表示了一个艺术家的记录,包括了姓名,年份和国家;其中一个特定的记录(record)被称为tuple(元组),它包括了该记录所有的参数(value),一般来说每个参数都是不能再细分的(数、字符串等等,不能是数据,向量),null参数是任何tuple的成员之一。在这个例子里我们可以说n-ary Relation = Table with n columns,一个n维的relation可以用一个n列的表格来表示。
在一个relation中我们可以用**primary key(主键)**来特定的标识出某个tuple,某一些DBMS会在你没有定义定义primary key的时候自动创建一个内部primary key,例如SQL:2003会产生一个序列、MySQL会自动递增一个序号,这时表格可能会下图这样子的,需要注意的是,这个id不代表记录的任何属性,只是我们用来标识出他的一个记号,这个记号也有可能不会显式地显示出来

除此之外,我们还需要有个机制来联系两个relation,所以还引入了一个foreign key(外键),这个键主要用来在一个tuple里面通过他来联系到另一个relation里面的另一个tuple,在这个例子指的就是艺术家和专辑之间的联系,如下图:
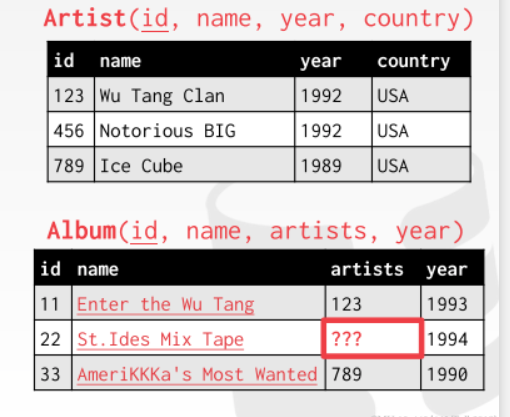
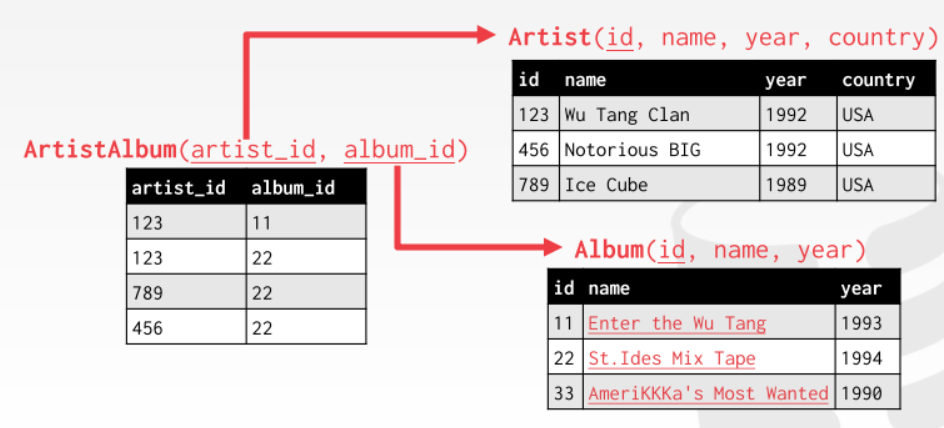
但是这里可以发现一个问题,但专辑不止有一个艺术家的时候怎么办?前面提到了每一个value必须是不可再分的,所以不能用一个数组来保存,这个时候我们可以用第三个relation来描述这两个relation之间的联系,这个relation里面每一个tuple只需要包含两个value:艺术家的id和专辑的id,如下图所示:
音乐商店例子:数据库操作
在确认了怎么表示一个数据库之后我们需要来操作它,这里我们主要关心把一个信息存进数据库和把它提取出来,这里主要两种方式:
- Procedural:每次查询制定好一个策略(不是具体的实现)用来给DBMS来执行查找
- Non-Procedural:查询操作不指定具体查找方法
这两种方式的具体应用分别是Relational Algebra(关系代数)和Relational Calculus(关系演算),这门课里面我们主要关注第一种查找方式。
Relational Algebra里面基于集合(没有重复元素)的运算法则规定了七种基本运算来获取和操作一个relation里面的tuple,其中每一个操作的输入是一个或多个relation,输出是一个新的reltaion:
| 符号 | 操作 |
|---|---|
$\sigma$ |
Select |
$\pi$ |
Projection |
$\cup$ |
Union |
$\cap$ |
Intersection |
$-$ |
Difference |
$\times$ |
Product |
$\Join$ |
Join |
下面对每一个操作进行介绍:
Select(选择)
选择操作是从一个relation里面选出一个tuple的子集满足给定的选择条件,作用和一个filter类似,具体语法是$\sigma_{predicate}(R)$,可以看看下面的例子,对同一个relation用不同的条件可以输出不同的结果(也是一个relation),这个操作对应SQL里面WHERE语句:

Projection(投影)
给定一个relation,投影操作可以输出一个只包括tuple里面的特定参数(attributes)新的relation,通过这个操作可以重新安排参数的顺序,也可以对所有tuple的某个参数进行统一的修改,效果和对应的SQL语句如下图所示,具体的语法是$\pi_{A1,A2,...,An}(R)$:

Union(并集)
联合操作比较简单,就是把两个relation合成一个新的relation,语法是$R\cup S$,效果如下所示,值得注意的是这个操作的两个输入relation需要有完全一样顺序的参数,否则不会匹配(另外这个例子里面好像不会去重??)

Intersection(交集)
对两个relation取共同部分,同样需要两个relation有完全一样的参数和顺序,语法是$R\cap S$:

Difference(差集)
差集的输入是两个relation,输出所有在第一个relation出现过但没有在第二个relation出现的tuple组成的relation,语法是$R-S$

Product (叉乘)
叉乘取两个relation作为输入,输出两个relation中各自所有tuple的排列组合产生的tuple并组成新的relation,语法是$R\times S$,类似SQL的cross join,效果如下

Join (联合)
Join取两个relation并输出一个新的relation,其中的tuple是这两个relation都包含的一部分(可能有共同的一个或多个参数),语法是$R\Join S$,类似SQL的NATURAL JOIN

其他
除了七种基本操作以外,relational algebra还有一些额外的操作,例如:Rename - $\rho$, Assignment - $R\leftarrow S$, Duplicate Elimination - $\delta$, Aggregation $\gamma$, sorting - $\tau$, Division - $R \div S$
相对于最初提到具体的某个具体的实现(for-loop),用relational algebra来实现某个查找相对来说虽然抽象程度更高,但是同一个查找可能不同的algebra实现方式可能效率不同,比如$\sigma_{b_{id}=102(R\Join S)} vs. (R\Join(\sigma_{b_{id}=102}(S)))$。对用户而言他在执行某个查找的时候只需要提出这样一个要求,来避免具体的实现细节(针对不同的数据库可能不同的执行顺序效率不同):
- Retrieve the joined tuples from R and S where b_id equals 102.
值得注意的是,虽然现在SQL已经是事实上的标准,relational model独立于任何一种特定的查询语言,用这种模型的好处是不需要去了解特定的实现细节(比如要不要用for循环去查找等等),而其中关系代数定义了关系数据库里面最基本的操作。