这是我在学习Databases Systems CMU 15-445/645/ Fall 2019过程记录的一些笔记。通过前两次课已经学习了一个数据库应该是怎么样的以及怎么通过sql去对数据库进行操作,接下来就是学习怎么样去构建一个数据库管理系统,这次课主要是介绍数据库的存储过程,主要是介绍了数据库里页的概念,以及不同方式去追踪页、存储页以及存储tuple。
存储结构
这门课研究的DBMS(数据库管理系统)都假定数据库的数据主要存储位置都是在非易失性存储空间( Non-volatile disk,硬盘等),而数据库管理系统的操作则是管理数据库从非易失性存储空间(硬盘)转移到易失性存储空间(内存),前三层是易失性的,在计算机断电之后数据不会保留,而后三层则是非易失性的,数据可以长期存储,在CPU进行运算时,需要把数据从后三层的空间转移到前三层。目前还有一种最新的存储技术叫非易失性内存(Non-Voltatile Memory, NVM),这种存储结构即有内存的高速度处理,也能像硬盘一样在断电之后也能保持速度,不过目前还在研究过程,没有普及。
一个典型的数据库存储层次结构如下所示,从上往下数据读写速度逐级递减:
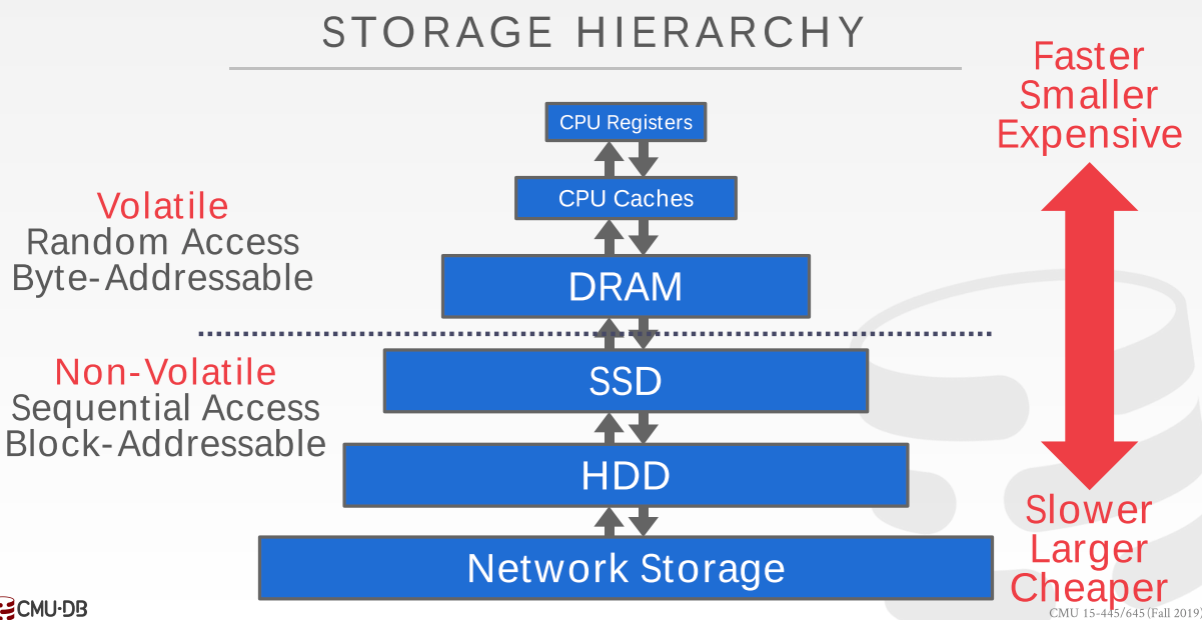
在这门课中我们主要关注后四层,把后三层统称为磁盘(Disk),DRAM称为内存(Memory),不同存储介质的读写速度可以参考下图,右侧是的数据主要是用来可视化长度对比。

系统设计
目标
针对DBMS,我们的设计目标主要是让整个系统可以管理一个数据库,它需要的空间会超过内存的可用空间(不超过的话直接全部读入内存就可以一直快速处理了)。并且用于对磁盘的读写代价太昂贵(速度太慢),所以我们需要尽可能避免大空间的读写而导致性能下降。
基于磁盘的数据库管理系统一个典型工作过程如下图:
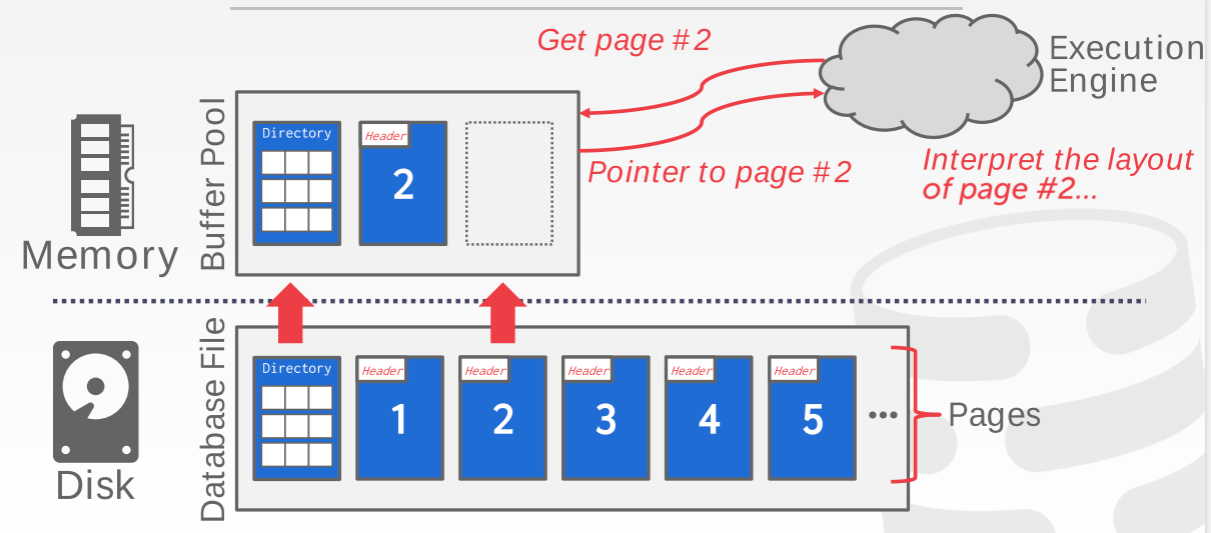
首先,处理器发出要求获得某个数据,此时内存里还没有该数据,需要从磁盘读取,读取之后再将该文件的指针给处理器,然后处理器进行运算,数据库则负责其中的数据转移和检查的部分,并不关心处理器会做什么运算。
从上面图以及目标来看,我们需要管理比实际内存空间要大的数据,那么为什么不直接用操作系统的虚拟内存机制然后让操作系统去管理读写操作而是去每次亲自读写内存和磁盘呢?
虚拟内存的原理大致如下图所示:操作系统维护一个虚拟的地址列表(memory-mapping, mmap),每次需要获取一页时会先在内存找有没有存好,如果没有就从磁盘读进来,有就直接访问。但是当实际内存存满数据的时候,操作系统需要决定清空哪个页面,而这个时候如果直接让操作系统来选择的话,并不可以根据数据库的性质已经查找命令做出有效率的选择,所以直接让操作系统选择并不好。
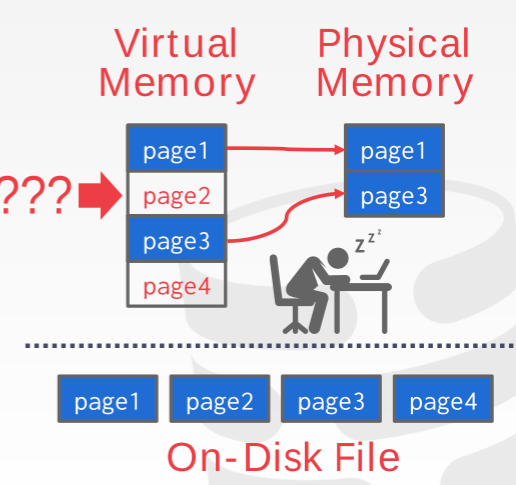
如果要解决这个问题的话我们有以下选择:
- madvise: 告诉操作系统你想要怎么样读取某页
- mlock:告诉操作系统那些页面需要保留
- msync:让操作系统把内存的数据存到磁盘去
目前市面上只有有部分DBMS (mongoDB, SQLite,…) 是采取这种策略去使用mmap,大部分都是历史原因。因为数据库管理系统本身总是能做到比操作系统来管理性能更高,主要集中在:
- 把用过的page 用一个合理的顺序flush到磁盘中
- 专门化的预处理某些数据
- 缓存替换策略
- 线程/线程调度
因为操作系统总是通用性的看待这些操作,所以数据库直接管理能做的更好,所以一般不让操作系统管理,本门课搭建的数据库管理系统也不会用到mmap。
数据库存储
数据库管理系统有很多模块,目前我们只关注存储模块,这一方面主要有两个问题:
- 数据库管理系统用什么样的方式表示磁盘里的数据库文件?
- 文件怎么存储?
- 数据库里面tuple怎么表示?
- 内存和磁盘里的页(page)怎么表示?
- 数据库管理系统怎么样管理磁盘和内存间的移动操作?
本文主要集中解决第一个问题。
文件存储
首先,DBMS 会将数据库文件写进一个或多个文件存在磁盘里。在操作系统的层面上并不关心文件的内容和格式,只要是符合一个通用的文件系统都能识别。但是对 DBMS 而言这是独有的,每个 DBMS 的数据库文件用别的 DBMS 都可能无法正确识别(早期的DBMS有一部分会用定制的文件系统来存储数据,但是现在几乎没有系统这样做了)。
存储管理器
首先我们需要有一个存储管理器来负责维护数据库的数据:包括对数据的读写调度来提高效率。对于存储管理器而言,文件在其的管理形式主要是表现为一系列的页(page),进而对数据的读写转为对页的读写读写和可用空间的管理。
数据库中的页
这里要区分一些数据库中的页和和操作系统的页的概念。这里的页(page)的概念主要是指一个固定空间大小的数据,可以包括tuples,元数据,索引和登录数据,大部分系统不会混着存储各种数据在一个页里面,比如tuple和索引会分开存储。 同时大部分系统都要求页里面应该包含关于页的所有数据,包括存储了什么以及怎么样去解析等等。这里主要是为了数据的安全性,假设我们有一个表,我们把表头放在一个page里而把所有的tuple放在另一个page里面,这个时候如果磁盘损坏存着表头的page无法读取了会导致包含tuple的页也没法发挥作用。
每个page都会被管理器分配一个独有的id(identifier)来进行空间上的追踪管理,这样当存储位置变了的时候管理器不需要改变页的id,只需要改变映射的地址就可以了,操作更加简介。
在数据库里面不同的page的操作如下表:
| 层次 | 大小 | 备注 |
|---|---|---|
| 硬件层面上的页 | 通常4KB | 能保证读写成功的最小单位,假如我们要写入16KB,其中每4KB的读写都可以认为是一次性完成,不存在写入到一半(比如2KB)失效的 |
| 操作系统的页 | 通常4KB | |
| 数据库的页 | 512B ~ 16KB | 不同数据库页的大小不一样,SQLite和Oracle的页大小4KB,mySQL页的大小是16KB |
页面管理架构
不同的数据库管理系统有不同方式去管理磁盘里面文件的page,大致有以下三种,这门课主要介绍第一种,堆文件组织。在这个层面上我们不需要知道page的具体内容是什么,只需要关心怎么存储页和读写。
- Heap File Organization (堆文件组织)
- Sequential / Sorted File Organization (序列文件组织)
- Hashing File Organization (哈希文件组织)
堆(heap)
堆文件指的是一个关于页的无序集合,并且支持页的创建/读取/写入/删除的操作,同时还需要可以遍历所有页。同时堆文件需要有元数据来追踪哪些页面已经存在以及哪些页面有空余空间。堆文件的表示方式有两种:
- 链表:目前比较少用
- 页目录
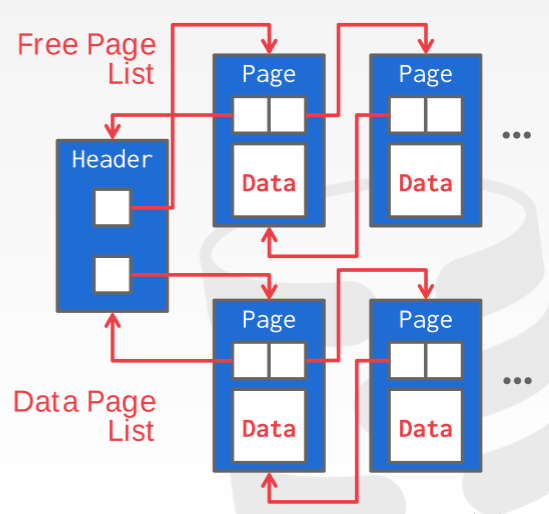
用链表的方法比较简单,只需要在文件起始位置存放两个链表的表头:分别是数据页列表的表头以及空页列表的表头,每个page追踪自身的可用空间,大致如下图所示。
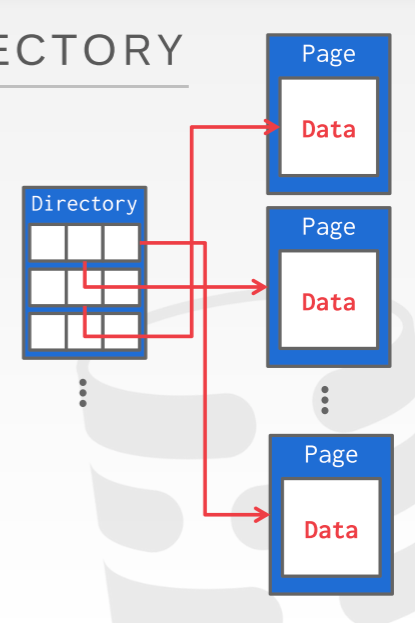
用页目录的方法需要DBMS 维护一个特定的页来通过数据页的id来追踪数据库中所有数据页的位置,并且记录每个页还有多少可用空间,因此很重要的一点是保证页目录和各个页需要同步(我们需要考虑当在页目录更新过程系统崩溃的话有什么机制能够让页目录能继续同步)。页目录的原理大致如下图所示:
Page layout
Page header 页头
每个页都包含一个页头来存储关于这个页的内容的元数据,主要包括以下几个参数,部分数据要求页面可以自我解析(例如Oracle,如上述):
- Page size: 尺寸
- Checksum
- BDMS version: 系统版本
- Transaction Vsiibility
- Compression
Page layout 页布局
对于页存储架构来说,我们现在需要理解怎么组织页内部的数据(上一部分关注怎么找到这个页),现在假设我们只存储tuples。有两种方式,分别是:
-
tuple-oriented
-
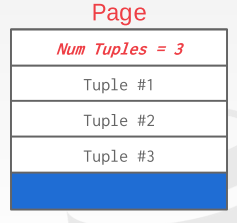
strawman 的方法:页面维护一个变量更新该页tuple的个数,每次往后面逐次添加tuple,如下图。这样的存储方式有一些问题:首先,当我们存的tuple是长度可变的值的话,当我们从中间删除一个tuple然后想添加一个tuple进去的时候,空间不一定匹配,另外我们需要遍历所有tuple找到我们想要的那个,效率比较低,所以目前比较少用。
-
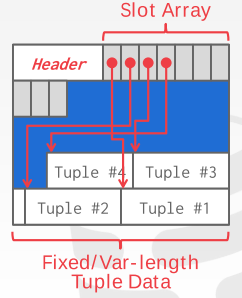
slotted pages:最常用的方案是在page分成两部分,前面部分存页头和一个slot 数组,每个数组位置存取到某个tuple的偏移量(offset),而后面部分则是存tuple数据,页头需要最终用过的slot的数量以及最后一个用过的slot的起始位置,大致原理如下图所示:
-
-
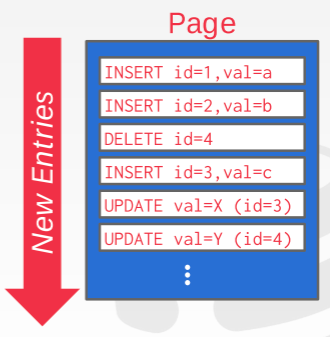
Log-structured:相对于存放tuple,log-sturctured 的组织方式存放的用户用户操作记录,如下图所示:每次操作往 page 插入一条新的 entry,插入新 tuple 的时候就在该 entry 存放 tuple,删除 tuple 或者更新 tuple 就查找该 tuple 的位置标记为已删除/更新参数,这种方法优点是便于回滚以及写入速度快,缺点是查找某个 tuple 的时候需要从后往前扫描来重新生成需要的 tuple,优化方法是可以生成 indexes 来定位tuple在 log 的位置,以及周期性的压缩记录(把更新和删除反映到 该 tuple 创建的 log 上,减少存放的 log 数量)
tuple layout
一个tuple一般都是一序列字节,由DBMS来解析字节理解具体的类型和值。每个tuple都有一个header包含所有元数据(可见性,null值的bitmap),这里注意我们不需要把数据库的schema存进去,只关注tuple本身。另外,tuple的参数存储顺序一般和我们创建他们的顺序是一致的。
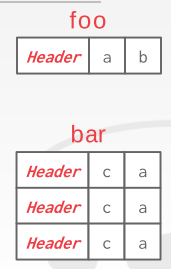
一般可以将相关的tuple存到同一个page(denormalization),这样有可能可以减少需要的I/O操作数,但是在更新的时候可能代价更高(更慢)。如下图,bar里面有foreign key指向boo,denormalization可以把他们的表头预先合在一起。(这种做法现在比较少用,一般不同table的tuple存在不同page里)
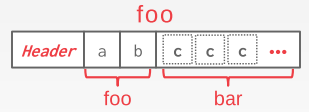
DBMS 需要用一个方式来管理每个单独的tuple,一般会对每个tuple 分配一个 record id,大部分的形式是:page_id + offset/slot(在上一部分提到的方式),也有可能还会存文件位置信息。但是这个信息每个DBMS的管理策略都不一样,用户不应该依赖这些信息表明顺序等等任何事情。