这是我在学习Databases Systems CMU 15-445/645/ Fall 2019过程记录的一些笔记,这次学习的第五课。总体来说,DBMS 在内存分配管理上能够比操作系统做得好很多(因为有对数据的额外信息),这次课主要包括了对内存的管理因为各类内存置换策略。
目标
这节课主要要解决的一个问题是:DBMS(database mangement system) 如何管理它的内存 (memory) 使用以及数据在磁盘( disk ) 之间的来回转移,主要从以下两个方面来体现:
- 空间控制:在磁盘的哪个位置写入 page,能够使得对于一起使用的 page 能够尽量保证他们在磁盘的位置也是靠近的
- 时间控制:什么时候读取 page 进内存以及什么时候将 page 写进磁盘,能够使得对磁盘的读写次数尽可能少
同样还是看下以磁盘为中心(主要存储位置)的 dbms 的结构:
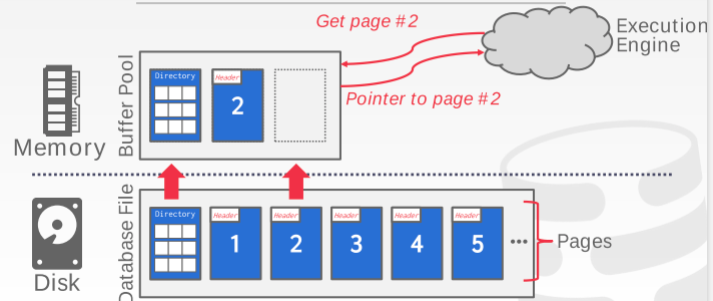
之前的课程已经介绍了关于 disk 的部分,也就是数据库如何在 disk 里面进行存储的,接下来要讲的是 memory 部分,主要是缓存池的管理已经数据的写入和写出。
Buffer Pool Manager (缓存池管理)
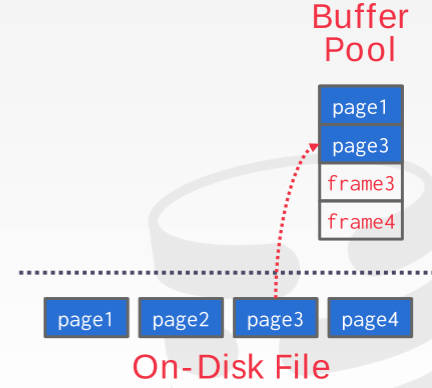
首先,看一下缓存池的组织结构。在内存的区域空间被分成一系列固定尺寸的 page 的数组,每个数组参数被称为一帧 (frame)。每当 DBMS 请求一个 page 的时候,缓存池会从 disk 里面复制(不做任何修改)一个 page 进入一个 frame 当中,如下图所示:
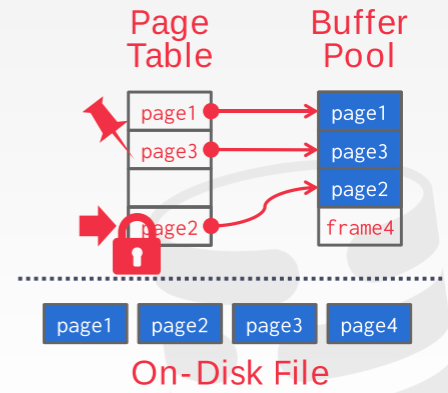
缓存池除了 frame 之外,还需要维护关于内存里存在的 page 的元数据(meta-data),主要通过 page-table来管理维护。 page-table 原理上是一个哈希表来追踪当前在内存里的 page,除此之外,对于每个 page 来说,还需要有一些额外的变量来维护其他信息,如 Dirty Flag (当前page从读入之后是否被修改过),Pin/Reference Counter (当前page 是不是正在被使用/被使用过多少次)等等。如下图所示:
在介绍缓存池管理方法之前,需要区分以下两个概念:
-
Locks:
- 保护数据库的逻辑内容不被其他传输(数据交换)干扰
- 在整个传输持续期间都在起作用
- 可以回退这个操作(撤销)
-
Latches:
- 保护 dbms 的关键部分(critical sections)不被其他线程干扰
- 整个操作期间保持
- 不需要可以回退操作
在操作系统里面我们常用的锁( mutex )其实是这里的第二个概念,更多的是关注不同线程在同一个区域共同操作的时候引起的互相干扰,数据库里的锁是第一个概念,需要实现的功能更加复杂一些,在底层也是通过 latches 来实现的。
接下来看一下页目录 (page directory) 和页表 (page table) 的区别:
- page directory: 通过 page ids 能够定位 page 在数据库文件中的位置(所有的修改都需要写入到 disk 里面,使得机器断电/重启后还能够使用)
- page table:通过 page ids 能够找到在缓存池里面的 page 对应的 frame 的位置(不需要长期保存,所以不需要保持在 disk 里面)
关于内存分配策略,有两种思路:
Global Policies (全局策略):做决定的时候考虑所有现存的传输记录(transaction)
Local Policies (局部策略):分配 frame 只关注当前某个传输记录,不需要考虑其他记录,但是同样需要可以支持 pages 在不同传输之间能工共享。
接下来讲一下缓存池的几种优化方法。
Multiple Buffer Pools
首先可以考虑使用多个缓存池,目前大部分商用的 DBMS 在使用的时候都不止有一个缓存池,可以根据不同分类来使用多个缓存池,比如:每个 table 使用一个缓存池/每个数据库使用一个缓存池或者每个 page 类型(tuple, index)使用一个缓存池。这样做的好处有:可以提高某些操作的运行速度,同时可以减少 latch 的使用提升效率(一个传输在修改 page-table 的时候,另一个传输操作可以同时访问另一个缓存池的 page-table 等等)。
有两种方法可以来维护多个缓存池,分别是:
- object id:可以在每个传输记录里面额外加一个 object id 来以此将其映射到某个缓存池中
- Hashing:可以直接通过哈希表的方式将 page id 映射到某个缓存池上。
Pre-fetching
我们还可以通过根据一个查询计划来提前读入一些pages,主要包括两种方法:顺序扫描(sequential scan),索引扫描(index scans)。具体参考下面例子:
假设我们要执行以下查询操作:
SELECT * FROM A
WHERE val BETWEEN 100 AND 250
然后我们对对应的 index-page 存储方式如下所示:

首先缓存池会顺序扫描 disk 上的页并读入到缓冲池中(page0, page1),当读取到 page1 的时候,通过 page1 我们知道 page3 的 val 是 100-199(二叉树存储);我们也知道我们需要查询的的范围是 100 - 250,所以我们可以根据我们是通过二叉树存储从而通过 page3 定位到 page5,并进而把那两个页面读入进来,而不需要逐一访问 page2, page4。我们之所以能够这么做是因为 DBMS 知道其内部是怎么存储数据的也能通过对 query 操作的分析来获取需要哪些 page,这是通用操作系统做不到的。
Scan Sharing
Scan Sharing 指的是,不同 queries 之间可以对其他 queries 的操作/或者存储的数据进行重复使用;允许多个 quries 重用一个扫描指针来扫描 table (共享扫描结果),可以共享中间结果。注意这个和对结果的缓存不是同一个概念(结果的缓存(result caching)指的是你在之前进行一个 query 操作之后结果被缓存了,当你再一起进行这个操作的时候可以直接获取上一次的结果),这里的不同 query 不需要完全一样,只要其中有部分中间操作有共同点就可以共享。
具体的实现方法可以是:当一个 query 开始对一个 table 进行扫描的时候已经有另一个 query 进行扫描的话, DBMS 会直接将第二个 query 的扫描指针放在正在进行的扫描指针上,同时 DBMS 会记录第二个 query 的扫描是在什么地方可以加入的,这样当扫描指针扫描到 table 结尾的时候可以从头开始并且知道到哪里结束。
目前已知 IBM DB2 和 MSSQL 支持这项技术。
Buffer Pool Bypass
在有一些操作的时候,通过 sequential scan 操作扫描的的 page 不会存储到缓存池里面,主要是因为:
- 对于一个 query 来说,内存本来就是局部的位置,当 query 结束的时候,内存里所有的frame 的 page 都会被释放,所以在某些情况不如直接绕过(尤其是当这些 page 不需要长期使用的时候)
- 当某个操作需要查找一个很长的而且在 disk 里面是连续的 page 的时候能够提升一点效率
- 也可以用在一些中间数据上(sorting, joins)
OS Page Cache
值得注意的时候,大部分有关 disk 的操作都是通过操作系统 api 来进行,除非特殊制定,否则操作系会维护自身的文件系统缓存。目前大部分 DBMS 通过 直接 I/O 来绕过操作系统的缓存(避免产生大量的 page 的副本和不同策略的冲突)。
这里建议看一下老师用 postgres 进行实际操作已经对 buffer pool 的演示。具体 Youtube 链接在这里,从40分钟左右开始。
Replacement Policies (置换策略)
这一部分主要讨论当 DBMS 需要释放掉某一个 frame 来放新的 page 的时候,应该怎么决定来使得:
- 正确性
- 准确性(释放的 page 短期内不会重用)
- 速度
- 元数据释放掉的话需要重新读取数据会使得效率下降
下面讨论几种方法
LRU(least recntly used)
这是一种比较常用的方法,通过维护每个页面上一次使用的时间戳,每次需要释放的时候, DBMS 释放掉一个最不经常使用(上一次使用时间最远)的page。另外可以通过对 page 进行排序来减少搜索的时间。
CLOCK
CLOCK 是一种对 LRU 的模拟方法,它不需要对每个 page 额外维护一个时间戳,具体实现方法如下:
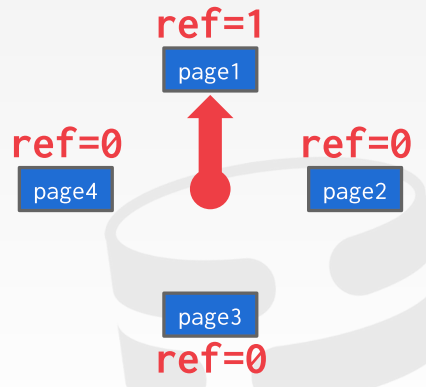
- 对每个 page 有一个 reference bit 记录是否被访问过(访问过之后设为 1)
- 将所有 pages 以一个环形来组织,如下图所示,在需要释放 frame 的时候,顺时针访问每个 frame:
- 如果当前 page reference bit 为 1,将其设为 0
- 如果当前为 0,就把他释放掉
LRU 和 CLOCK 的问题
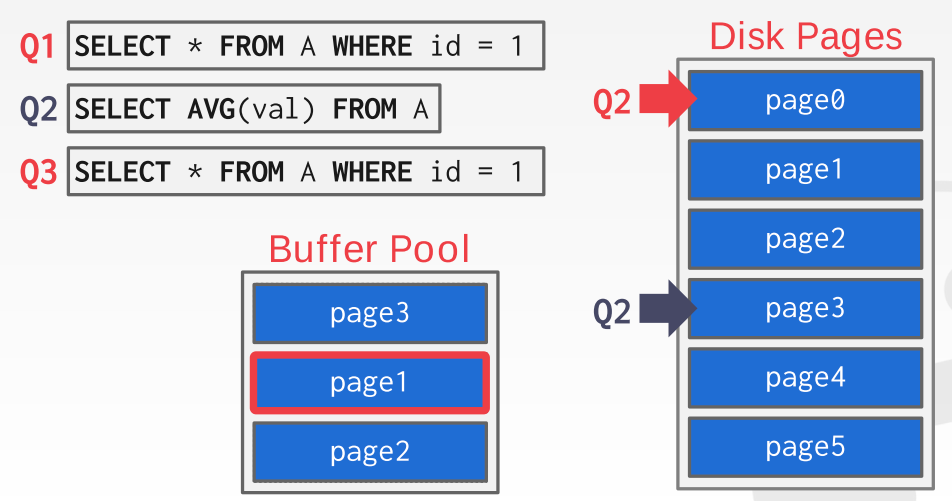
对于一个序列操作来说(扫描整个table),LRU 和 clock 反而可能会使效率下降,因为大部分数据只会在扫描的时候被读入进来一次然后再也不会使用,这样的话,最经常使用的 page (最后一个被扫描进来的) 实际上可能是最不需要的 page,具体可以参考以下例子,执行 Q1 的时候先把 page 0 读进来,然后执行 q2 的时候因为是一个扫描操作所以按顺序读取 page1 和 page2 进来,当需要读 page3 的时候,因为 lru 所以把 page0 释放掉了,注意如果我们接下来执行的 q3 和 q0 一样化,page0 才是我们需要保留的:
改进的策略
- 追踪前 k 个被访问的 page 并根据时间戳来计算某个相邻 page 的访问时间,并以此来估计当前 page 下一次被访问的时间。
- 定位:DBMS追踪每个 query 使用的 page,并针对其来进行选择哪个释放,这样可以最大程度的避免因为一个 query 的操作来将另一个 query 常使用的page 释放掉
- 优先级提示:因为DBMS知道query中涉及的每个 page 的内容,可以用它来提示哪个 page 更加重要
Dirty Page
我们有两种方式来处理 dirty page(被修改过的):
- 快速方法:如果当前 page 没被修改过,可以直接释放掉,无需和 disk 进行交互
- 慢:如果当前 page 修改过,需要将其重新写入 disk
我们选择哪类 page 来释放的时候需要考虑 trade off: 快速释放没被修改过的 page (但是有可能经常访问)还是 写入一个在短时间都不会访问的但是被修改过的 page。DBMS 可以周期性的进行一些后台访问 page table 并将 dirty page 写入 disk 里然后重置它的 dirty flag(但是需要注意不能再 dirty flag 被设为1和 该页实际被修改之间的时间进行写入!)。