简介
在标准里面,C++ 中的模板可以是:
- 类模板:一系列类,这些类可以是嵌套类
- 函数模板:一系列函数,这些函数可以是类的成员函数
在不同的标准里面,还有一些新的定义:
- (C++14)别名模板:一系列类型的别名
- (C++17)变量模板:一系列变量
- (C++20)TODO
模板可以通过模板参数来进行参数化来产生我们需要的内容,下面对较常用的函数模板进行整理。
函数模板
普通函数
函数模板,顾名思义是函数的模板。当我们需要对很多不同类型的变量进行相似的操作,如果不用模板,那么我们可能需要自己编写大量相似的函数,如下所示:
int getSum(int* arr, int N) {
int sum = 0;
for (int i = 0; i < N; ++i) {
sum += arr[i];
}
return sum;
}
double getSum(double* arr, int N) {
double sum = 0;
for (int i = 0; i < N; ++i) {
sum += arr[i];
}
return sum;
}
int main() {
int a[5] = {1, 2, 3, 4, 5};
int i_sum = getSum(a, 5);
double b[3] = {1.0, 1.5, 2.0};
double d_sum = getSum(b, 3);
printf("sum of a = %d, sum of b = %f.\n", i_sum, d_sum);
return 0;
}
运行结果:
$ /home/xt/code_collections/cpp/build/templates/template_example1
sum of a = 15, sum of b = 4.500000.
如上所示,两个重载的 getSum() 函数中,除了类型以外其他操作完全一致,这样的代码是不太好的,因为大量同名函数造成可读性下降,同时维护起来也比较麻烦,如果我们需要改变函数的逻辑,那么我们需要对所有函数都需要一遍,容易遗漏导致出错。因此使用模板可以很好的解决这个问题,如下所示:
template <typename T>
T getSum(T* arr, int N) {
T sum = T(0);
for (int i = 0; i < N; ++i) {
sum = sum + arr[i];
}
return sum;
}
int main() {
int a[5] = {1, 2, 3, 4, 5};
int i_sum = getSum(a, 5);
double b[3] = {1.0, 1.5, 2.0};
double d_sum = getSum(b, 3);
printf("sum of a = %d, sum of b = %f.\n", i_sum, d_sum);
return 0;
}
运行结果:
$ /home/xt/code_collections/cpp/build/templates/template_example1
sum of a = 15, sum of b = 4.500000.
这只是非常简单的一个例子,但是可以用来说明问题,函数模板本身不是函数,只是用来生成函数的模板。编译器会根据我们指定(或推断)的参数类型来为我们编写这个函数,如果我们从头到尾没有使用过这个模板,那就不会有多余的函数被生成,这就是为什么模板不会在编译产生的目标文件中占有空间。理解这一点对理解模板的很多特性都很有帮助。
我们可以通过汇编(不开优化)来理解这一过程,先看不带函数模板的结果:

换成模板实现的结果:

可以看到,编译结果除了函数签名稍微有点区别以外(带了模板参数),其他部分完全一致。那么如果我们不调用这个函数呢?
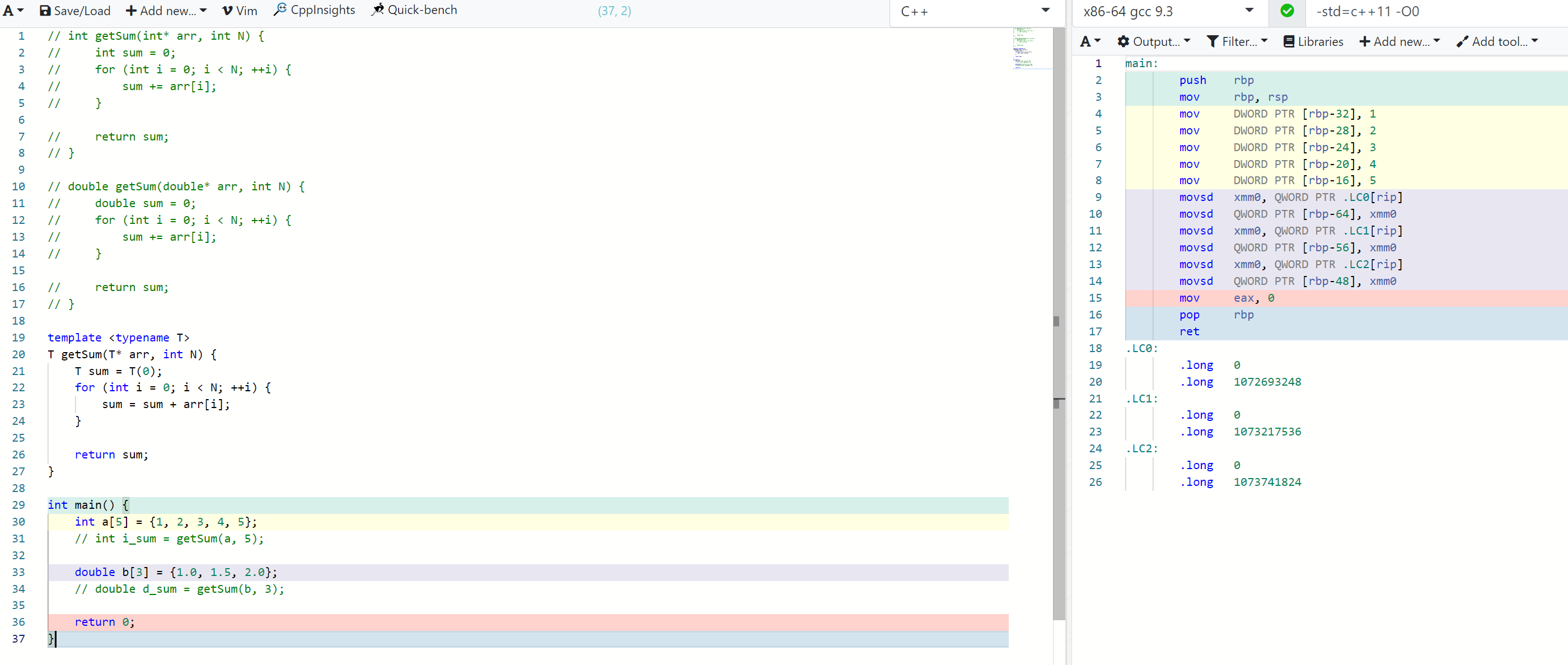
模板本身不会被编译,也不会产生任何代码,因此不会在运行时产生任何额外的开销。(注:在编译过程中可能产生额外的开销,见后面 extern template 部分)。
成员函数
函数模板不仅能用在普通函数上,也可以用在类的成员函数上,如下所示:
#include <stdio.h>
#include <string>
class Base {
public:
Base(const std::string& id, int num) : id_(id), num_(num) {}
void assignID(const std::string& new_id) { assign(new_id, id_); }
void assignNum(int new_num) { assign(new_num, num_); }
void info() { printf("Id: %s, num: %d\n", id_.c_str(), num_); }
private:
template <typename T>
void assign(T src, T& dst) {
dst = src;
}
std::string id_;
int num_;
};
int main() {
Base b("A", 10);
b.info();
b.assignID("B");
b.info();
b.assignNum(20);
b.info();
return 0;
}
运行结果为:
$ /home/xt/code_collections/cpp/build/templates/template_example2
Id: A, num: 10
Id: B, num: 10
Id: B, num: 20
模板和虚函数
那么如果我们想结合模板和虚函数的优点实现一个虚函数的模板呢?类似于以下例子:
class Base {
public:
Base(const std::string& id, int num) : id_(id), num_(num) {}
void assignID(const std::string& new_id) { assign(new_id, id_); }
void assignNum(int new_num) { assign(new_num, num_); }
void info() { printf("Id: %s, num: %d\n", id_.c_str(), num_); }
// Wrong! won't work
template <typename T>
virtual void doThings() {
// do something in base
}
private:
template <typename T>
void assign(T src, T& dst) {
dst = src;
}
std::string id_;
int num_;
};
class Derived : public Base {
public:
// Wrong! won't work
template <typename T>
virtual void doThings() override {
// do something in derived
}
};
程序会在编译阶段报错:../templates/example2.cpp:15:5: error: templates may not be ‘virtual’ 提示模板不能是虚的。具体原因可能有很多,但从语义上来看的话虚函数和模板显然是冲突的,模板相当于给给编译期一个模板,让编译器在编译时根据你调用了哪些函数来对模板进行实例化。但是虚函数相反,虚函数依赖于虚函数表,在运行时才能确定调用哪个函数。因此和模板本质上是冲突的。
函数模板实例化
在前一部分中我们提到函数模板本身不是函数,只有在通过实例化之后才能生成函数,因此像普通函数一样,我们需要提供对应的模板函数的声明和定义,让编译器根据编写的函数模板来对对应实例进行实现。上面的例子基本上都是隐式实例化,因此我们看不到模板函数的定义和声明,下面我们来看一下具体的实例化方法。
显式实例化
最简单的方式是显式提供模板函数的完整定义式,包含所有模板化参数,在可以从函数入参推导参数时也可以省略,如下所示:
template <typename T>
T getSum(T* arr, int N) {
T sum = T(0);
for (int i = 0; i < N; ++i) {
sum = sum + arr[i];
}
return sum;
}
template int getSum<int>(int*, int); // 定义式 1,提供完整参数类型
template double getSum(double*, int); // 定义式 2,省略参数类型,参数类型可以从返回参数推断
template float getSum<>(float*, int); // 定义式 3,省略参数类型,参数类型可以从返回参数推断
上面例子中,我们提供了三个模板函数的定义式,因此编译器会在当前编译单元完成三个模板函数的实现。那么可想而知,如果我们在多个编译单元中都包含了定义式。那么整个程序中就会包含多份一样的实现代码。如下所示:
// utils.hpp
#pragma once
#include <iostream>
template <typename T>
T getSum(T* arr, int N) {
T sum = T(0);
for (int i = 0; i < N; ++i) {
sum = sum + arr[i];
}
return sum;
}
void func1();
void func2();
// main.cpp
#include "utils.hpp"
int main(int argc, char **argv) {
func1();
func2();
return 0;
}
// func1.cpp
#include "utils.hpp"
template int getSum(int*, int);
void func1() {
int a[5] = {1, 2, 3, 4, 5};
getSum(a, 5);
}
// func2.cpp
#include "utils.hpp"
template int getSum(int*, int);
void func2() {
int a[3] = {1, 2, 3};
getSum(a, 3);
}
通过 g++ -c func1.cpp -c func2.cpp -c main.cpp 将每个源文件编译成 object 文件,通过 nm 查看里面包含的符号。
$ nm main.o func1.o func2.o
main.o:
...
U _Z5func1v
U _Z5func2v
...
0000000000000000 T main
func1.o:
...
0000000000000000 T _Z5func1v
0000000000000000 W _Z6getSumIiET_PS0_i
...
func2.o:
...
0000000000000000 T _Z5func2v
0000000000000000 W _Z6getSumIiET_PS0_i
...
可以发现,func1.o 和 func2.o 各包含了一份 _Z6getSumIiET_PS0_i 且已被定义,因此每个编译单元中都会都会包含一份 getSum 的实现。如果被包含的次数很多的话,有可能会造成代码膨胀。在对产生可执行文件的大小有要求时,我们可以在大部分使用到的函数模板的编译单元中只提供声明,让编译器知道不需要在这份编译单元里进行实例化。最后需要自己保证在至少一个编译单元处提供该模板函数的定义式,模板函数的声明式为在定义式前加 extern 即可,如下所示:
// utils.hpp
#pragma once
#include <iostream>
template <typename T>
T getSum(T* arr, int N) {
T sum = T(0);
for (int i = 0; i < N; ++i) {
sum = sum + arr[i];
}
return sum;
}
void func1();
void func2();
// main.cpp
#include "utils.hpp"
int main(int argc, char **argv) {
func1();
func2();
return 0;
}
// func1.cpp
#include "utils.hpp"
template int getSum(int*, int);
void func1() {
int a[5] = {1, 2, 3, 4, 5};
getSum(a, 5);
}
// func2.cpp
#include "utils.hpp"
extern template int getSum(int*, int);
void func2() {
int a[3] = {1, 2, 3};
getSum(a, 3);
}
同样分别生成 .o 文件之后查看里面的符号,如下所示。可以发现,在 func2.cpp 用 extern 标记了 template int getSum(int*, int); 之后,相当于告诉编译器不需要在这份编译单元里面提供这个模板的实例。但是这并不保证模板一定会在某个编译单元进行实例化,因此我们需要在其中一份源文件中显示的提供该函数的定义,即 func1.cpp 中的 template int getSum(int*, int); 这样编译器会在这份编译单元中对其进行实例化。(我试过不加这个定义语句发现也能顺利编译和链接,需要后续确认一下是否确实需要显式的提供定义。)
$ nm main.o func1.o func2.o
main.o:
...
U _Z5func1v
U _Z5func2v
...
0000000000000000 T main
func1.o:
...
0000000000000000 T _Z5func1v
0000000000000000 W _Z6getSumIiET_PS0_i
...
func2.o:
...
0000000000000000 T _Z5func2v
U _Z6getSumIiET_PS0_i
...
隐式实例化
隐式实例化不需要提供声明或者定义,当代码调用了函数且需要函数定义存在时(未被标记为 extern),编译器会自动对其进行实例化。之前的例子都是隐式实例化。
函数模板特例化
接下来看一下函数模板实例化可能涉及的问题,以下为例子:
#include <iostream>
template <typename T1, typename T2>
void showTwoEntities(T1 t1, T2 t2) {
std::cout << "General template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
int main() {
showTwoEntities(10, 10);
return 0;
}
运行结果:
General template: 10, 10
看起来没啥问题,但如果我们想对某些特定的类型,做出特殊的处理呢?比如对 T1 = std::string , T2 = int 我们输出别的内容呢?C++ 提供了对模板特例化的特性,如下所示:
#include <iostream>
template <typename T1, typename T2>
void showTwoEntities(T1 t1, T2 t2) {
std::cout << "General template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
template <>
void showTwoEntities(std::string t1, int t2) {
std::cout << "Specialized template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
int main() {
std::string str = "A";
int num = 10;
showTwoEntities(num, num);
showTwoEntities(str, num);
return 0;
}
运行结果为:
General template: 10, 10
Specialized template: A, 10
这个特性非常好用,尤其在我们使用第三方库时(如 PCL)想使用该库的某些函数,但是又想对自己提供特殊的数据结构进行特例化就可以使用这个特性。
如此一来,就带来一个匹配顺序的问题,见以下例子:
#include <iostream>
void showTwoEntities(std::string t1, std::string t2) {
std::cout << "No template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
template <typename T>
void showTwoEntities(T t1, T t2) {
std::cout << "Single type template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
template <typename T1, typename T2>
void showTwoEntities(T1 t1, T2 t2) {
std::cout << "General template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
template <>
void showTwoEntities(std::string t1, std::string t2) {
std::cout << "Specialized template: ";
std::cout << t1 << ", " << t2 << std::endl;
}
int main() {
std::string str = "A";
showTwoEntities(str, str);
return 0;
}
上述例子中,showTwoEntities(str, str) 可以对应上 4 种函数的签名,且 C++ 允许它们同时存在。那么他们之间的匹配优先级是怎么样的呢?我们通过测试来看一下:
# 不注释
No template: A, A
# 注释普通函数
Specialized template: A, A
# 注释普通函数和特例化模板
Single type template: A, A
# 注释掉普通函数、特例化模板、单参数模板
General template: A, A
可以发现,非模板函数匹配优先度最高,齐次是特例化的模板函数,最后两个非特例化的模板函数这里编译器是优先匹配了只有一个模板参数的版本。不过我没在标准找到明确规定,所以不确定是否适用于所有情况。但是我们也可以显式的指定模板参数来确保编译器调用了我们想要的那个模板:
int main() {
std::string str = "A";
showTwoEntities<std::string, std::string>(str, str);
return 0;
}
运行结果:
General template: A, A
可变参数模板
C++11 提供了一个新特性,可以允许模板接收零个或多个任意类型的参数。由于我也不是很熟悉,因此这里就简单介绍一下它的基本用法,关于其它更深入的内容等将来有机会使用时再整理。下面以一个小例子来体会一下这个特性:
#include <iostream>
template <typename T>
T getSum(T t) {
return t;
}
template <typename T, typename... Types>
T getSum(T first, Types... rest) {
return first + getSum<T>(rest...);
}
int main() {
std::cout << "sum: " << getSum(1, 2, 3.0, 4) << std::endl;
return 0;
}
从这个例子可以看出可变参数模板的基本用法。这个例子中,我们想要获得一组数据的和,这里我们没有像博客开头一样使用一个单类型函数模板来对数组进行遍历,而是使用了一个可变参数函数模板。模板中多个地方使用了 ...,它们的意义分别是:
typename... Types:表明Types是一个可变模板参数Types... rest:表明rest是一个可变参数类型的形参rest...:表明传入的rest为可变参数类型的,可以进行展开
因此这里相当于递归的调用了模板函数,每一次调用会将第一个参数拿出来和后面参数递归结果进行相加。最后的 base case 为传入参数数量只有一个时:会优先调用 T getSum(T t) 返回它自身。假如没有这个函数会怎么样呢?由于 rest 本身可以为 0 个参数,因此会递归调用自身,最后编译失败。
这个例子也体现了可变参数函数模板的两个重要性质:首先,类型是可变的,这里我们可以将 1 和 3.0 进行相加,而在非可变参数的函数模板上我们需要做到这一点比较麻烦。第二点,之前提到函数模板本身不是函数,编译器在编译过程为我们“编写”了需要的函数。那么对于可变参数模板,编译器是怎么编译的呢?我们直接看一下这个例子的汇编结果:
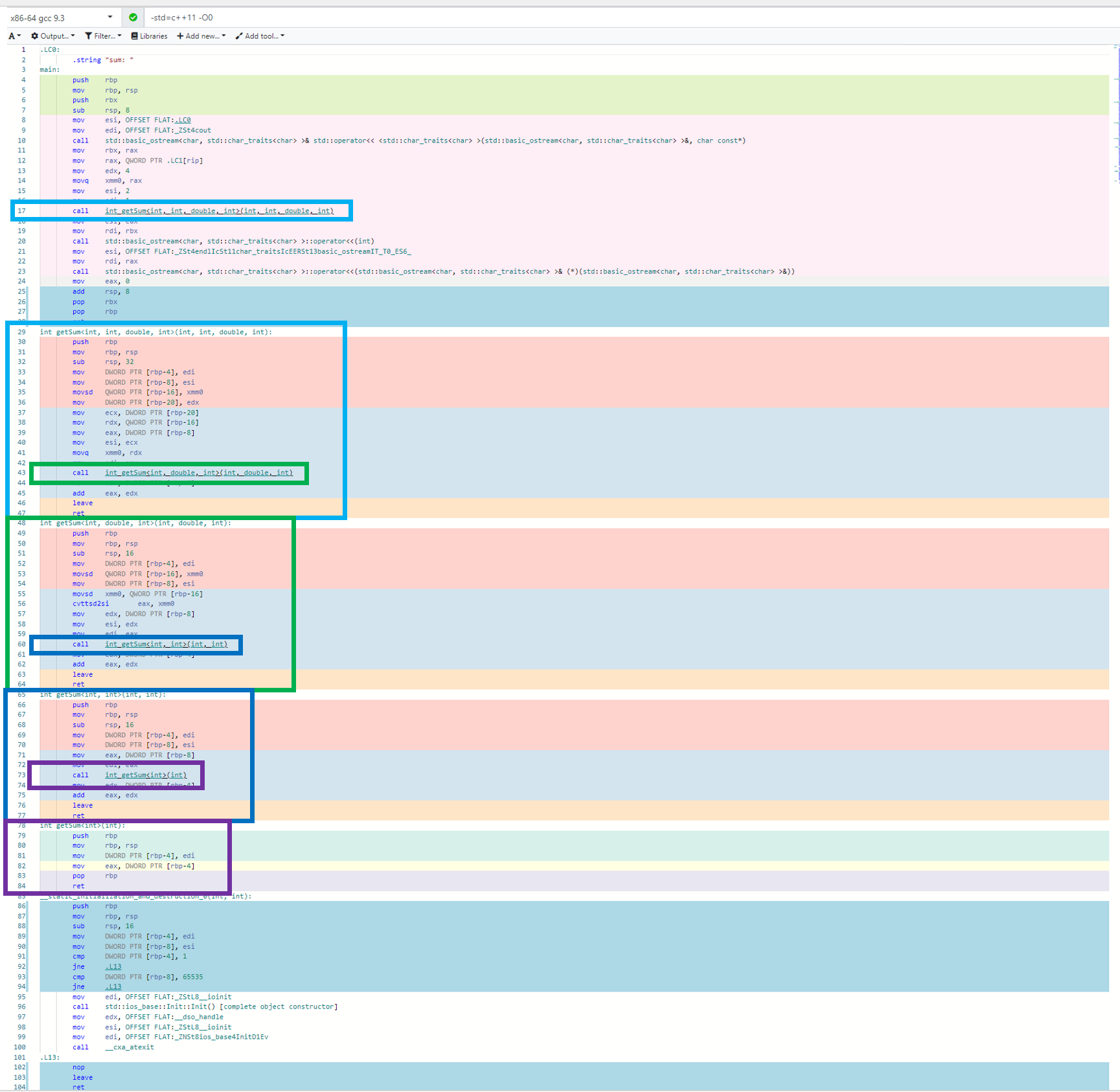
可以看到,编译器通过分析调用逻辑顺序,为我们生成了调用时所需要的所有参数,并依次调用。也就是说,参数包 1, 2, 3.0, 4 在编译期其实就经过了一次遍历!利用这个性质可以实现很多有趣的事情,例如这个大佬通过可变参数模板实现了一个编译期的选择排序:C++模板元编程—-选择排序