简介
原论文见:How to Keep HD Maps for Automated Driving Up To Date。论文主要是为了将自动驾驶汽车行驶过程中收集到的数据利用起来,用来保持高精地图和现实的一致性。
论文将高精地图和环境的不一致分为以下几类:
- 包含建筑工事的环境变化:这类变化在地图和环境不一致的地方通常有建筑标志物或指示牌出现
- 不包含建筑工事的环境变化:这类变化通常发生在一个建筑工事结束之后
- 建图错误:由建图过程的误差导致的和环境不一致
上述三类不一致的情况中,第一类可以由对建筑标志物的检测来确定,但是另外两类暂时没有比较很好的适用于大规模场景下的检测方法。这篇论文的贡献在于:
- 提出了一个系统将众包数据用于持续保持高精地图和环境一致,检测范围包含上述所有地图和环境不一致的情况
- 该方案可以基于道路网络进行大规模扩展
- 针对环境地图学习,提出了比以往更好的算法
数据介绍
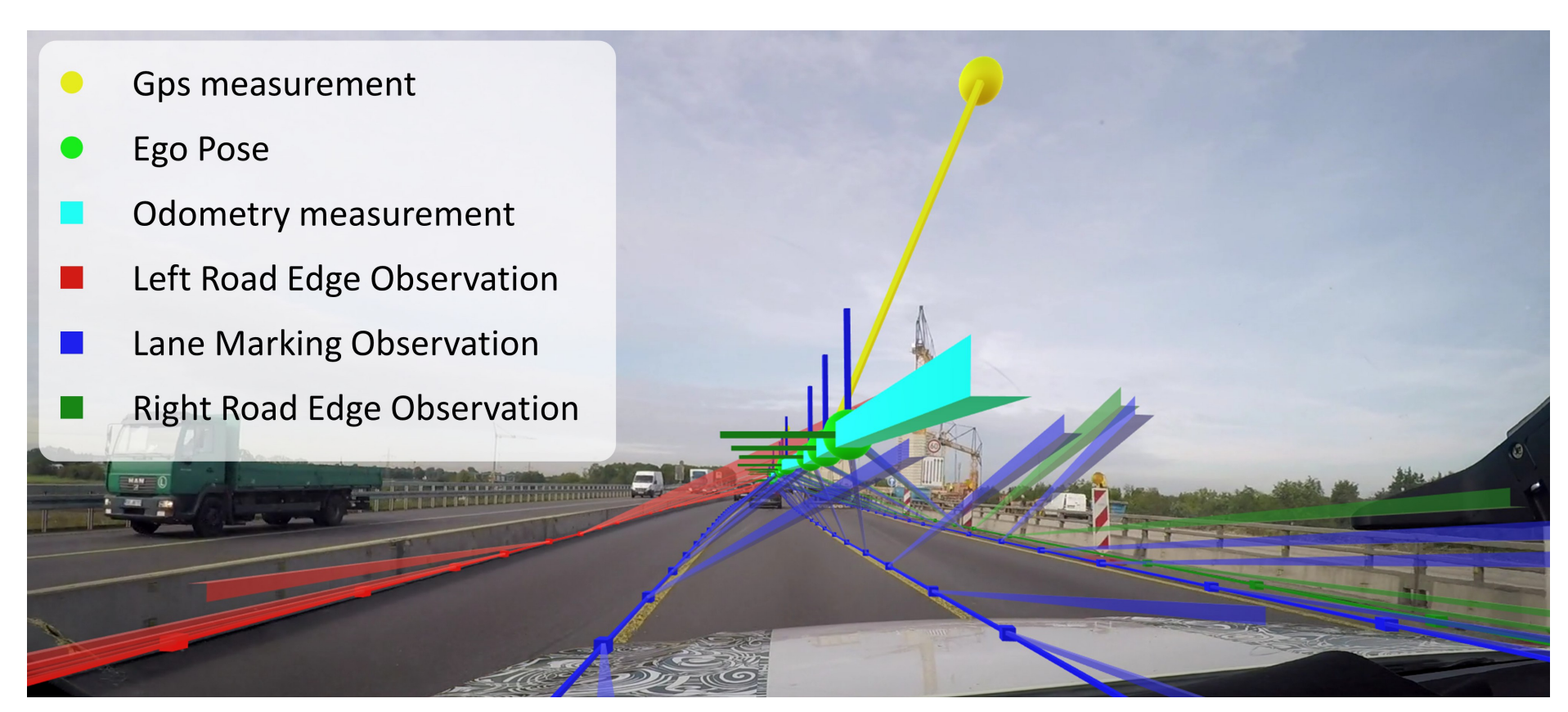
作者使用的数据从大量装备有照相机以及网络连接的车获取。将同一区域的所有遍历记为:$\tau =\{ t^1,..., t^{N_\tau}\}$,$N_{\tau} = |\tau|$ 为遍历总数。每次遍历的传感器数据 $t^i$ 包括一系列 6 自由度的里程计测量 $\boldsymbol{u}^i$,3 自由度的 GNSS 位置测量 $\boldsymbol{g}^i$ 和环境数据观测 $\boldsymbol{z}^i$,如下所示:
$$
t^i = \{\boldsymbol{u}^i, \boldsymbol{g}^i, \boldsymbol{z}^i\}
$$
所有的测量值和观测值都附带一个时间戳,可以用来进行不同类型的测量和观测值进行时间上匹配。每个环境观测 $z\in\boldsymbol{z}$ 表示观测到的路标(landmark)或者道路边缘类型(road edge)的信息。并附有一个区域界限 ID $B(z) \in \mathbb{N}$。对于所有遍历 $t^i$ 中同属于一个区域的的观测 $z^i_k$ 会统一分配一个 ID $b^i$,通过这种方式,可以将观测按区域来进行划分:
$$
\zeta_b = \{z^i_k: i \in \{1, ..., N_\tau\}, k \in \{1, ..., N_z^i\}, B(z_k^i) = b^i\}
$$
汽车本身的轨迹用一系列随机变量 $\boldsymbol{x}^i$ 来表示。下图展示了从单次遍历的轨迹、测量值以及环境观测。
解决方案
论文提出的解决方案的整体思路为:将从汽车上获取的传感器数据和地图作比较,估计环境变化的概率,并在需要的时候进行地图更新。系统包含以下几个流程:变化检测、工作创建、地图更新,下面进行详细介绍。
问题分解
为了精准定位变化发生的区域,不能笼统的对整个地图进行变化评估,因此需要将问题进行分解。作者提出了两种问题分解的思路:
- 按照地理信息将地图分成若干个瓦片(tiles)
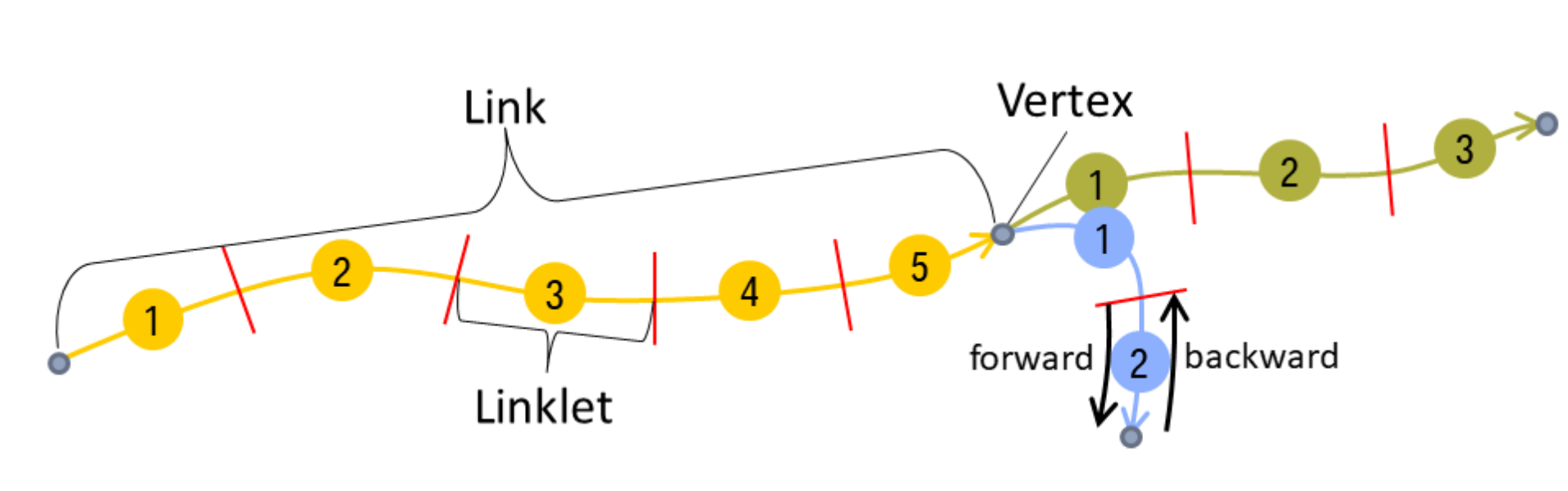
- 利用道路网络之间的拓扑信息,将地图视为一系列节点(道路的交点)和边(道路),将地图分解成若干条边。每条边又可以被称为道路链接(road links)且包含额外的信息如道路形状等。
作者认为如果按照第一种思路划分,智能保证每个区域有一定数量遍历,但每个区域内部的遍历频率差别会很大,例如高速公路和乡村小路(很难保证这两种道路会有相同更新机会)。因此他们采用第二种分解思路,这样分解的优点是,他们可以很简单获取每条路最近的汽车遍历数据,而不需要考虑他们的遍历频率。
作者将汽车数据和数据库中的标准道路拓扑地图进行匹配,对拓扑地图中的每条道路可以提取对应的高精地图信息。由于拓扑地图中每条边的长度(形状)$|S|$可能不同,为了控制以及统一各个问题规模,作者提出了一种新的道路划分概念。对于一个给定的目标模块长度 $l_{\text{target}}$,对每一条边的划分数量由下式决定:
$$
n^*_S = \arg\min_{n\in\mathbb{N}}\left|\frac{|S|}{n} - l_{\text{target}}\right|
$$
这样可以将每条道路划分成相同长度的模块 $\mathbb{Y} = \{y_1, ..., y_{n_S^*}\}$,每个部分的长度在 $l_{\text{target}}$ 附近,并且作者将遍历方向分为前向和反向两种 $\mathbb{D} = \{\text{forward}, \text{backword}\}$。因此,对于一个给定形状的道路链接集合 $L_S$ 可以定义如下:
$$
L_S = \{(y, d): \forall y \in\mathbb{Y}_s, \forall d \in \mathbb{D} \}
$$
而一个拓扑地图 $H$ 中的道路链接可以按形状进行划分:
$$
L = \{L_S: \forall S(E) \in H \}
$$
而对于高精地图而言,可以按照拓扑地图中的道路链接的不同部分来进行划分:
$$
m = \{m_1, ..., m_{l_{N_L}}\}
$$
下图展示对道路链接的划分以及标准地图中边和节点的关系:
方法介绍
为了对问题进行建模,作者引入一个随机变量用于描述环境变化的概率。令 $(\mathbb{W}, P)$ 为所有环境状态的概率空间,$\mathbb{M}$ 为所有地图情况的无限空间。对于每个分块的地图 $m_l \in \mathbb{M}$ 定义以下离散随机变量 $C_{m_l} \: \mathbb{W} \rightarrow \{0, 1\}$:
$$
C_m(w) =
\left\{
\begin{aligned}
1 \qquad &\text{环境} w \text{相对于} m_l 发生了变化\\
0 \qquad &\text{环境} w \text{相对于} m_l 没有发生变化
\end{aligned}
\right.
$$
对于我们的问题而言,我们需要持续对当前版本的子图 $m_l^0$ 进行发生环境变化的概率分析:$P(C_{m_l^0} = 1)$。此外,还需要时刻更新高精地图来降低这个概率:$m^*_l = \arg\min_{m_l\in\mathbb{M}}P(C_{m_l} = 1)$。
下面对这两部分进行详细描述。
变化概率估计
由于环境状态和变化概率无法直接观测,因此需要基于车辆遍历数据来进行估计。将某个局部链接 $l$ 的所有遍历数据记为:$\tau_l = t^1_l, ... t^{N_{\tau_l}}$。将其中所有子集的集合记为:$\mathfrak{B}_l(T_l)$。作者想要找一个最好的概率估计函数 $F*$ 来对所有局部地图的变化概率进行计算:$F: \mathbb{M} \times \mathfrak{B}_l(T_l) \rightarrow [0, 1]$。为了找到这个最优估计,作者使用了一个训练数据集,对于每个局部区域 $L_g\subset L$,包括子图 $m^0_l$,一系列遍历数据 $t_l\subset T_l$ 和对应真值信息 $P(C_{m^0_l} = 1)$,因此求解问题为:
$$
F* = \arg\min_{F}\sum_{l\in L_g}|F(m_l^0, \tau_l) - P(C_{m_l^0} = 1)|
$$
接下来作者将问题进一步简化为对单次遍历的变化概率估计,这样获取了所有遍历的信息,再汇总形成一个结论。因此接下来要寻找最优估计函数 $f*: \mathbb{M} \times \tau_l \rightarrow [0, 1]$ 用来对某个区域的单次遍历 $t^i_l$ 以及给定地图版本 $m^0_l$ 进行概率估计。作者的做法是是对上述训练集进行回归分析,如下所示:
$$
f^* = \arg\min_f\sum_{l\in L_g}\sum_{t^i_l \in \tau_l} (f(m_l^0, t^i_l) - P(C_{m^0_l} = 1))^2
$$
然后对所有结果的汇总函数为:
$$
F^*_a(m_l, \tau_l) = a(f^*(m_l, t^1_l), ..., f^*(m_l, t^{N_{\tau_l}}))
$$
$a$ 的选择对地图优化策略有很大影响,这里作者给出两个例子,一种是对函数结果求平均(即每次遍历的权重一致),还有一种是只考虑变化概率超过一定概率的遍历结果,然后求平均(即将权重更多集中上发生变化的遍历上)。
地图更新
对于地图更新,目标对所有发生变化的区域,估计高精地图 $m^*_l$ 来对变化概率进行最小化。同样,由于变化概率无法直接测量,因此通过之前的方程进行评估:
$$
m^*_l = \arg\min_{m_l \in \mathbb{M}}F^*_a(m_l, \tau_l)
$$
系统总览
整体解决方案的系统总览图如下所示:

整体可以分为三个部分:首先环境变化检测模块持续对地图中每个区域的变化概率进行评估,周期性触发工作创建流程来创建地图更新任务,然后地图更新模块对高精地图进行更新。
变化检测流程 (Change Detection)
环境变化检测模块对每一个输入的轨迹以及相关信息进行处理,主要分为以下三个流程:
- 轨迹预处理:主要是进行基于 GNSS 的 SLAM 过程对轨迹进行优化,然后将 SLAM 过程中生成的地图和先验高精地图进行匹配,最后将单次遍历数据按不同区域进行划分
- 基于单次遍历的变化概率估计:接下来将地图中的不同特征按照最近邻规则在观测中进行一一匹配,匹配最大距离设置为 2.5m。将这些特征汇总形成特征误差向量,然后利用回归的方式来预测每次区域遍历时的环境变化概率。作者将观测和地图中的特征比较转换至车辆坐标系统,计算以下参数。然后特征向量被传入至一个梯度增强树(Gradient Boosted Tree Regressor),最后输出针对这次遍历的变化概率估计。
- 路标偏差的切向标准差
- 路标偏差的侧向标准差
- 道路边缘的观测绝对侧向偏差
- 所有观测的侧向标准差
- 没有被分配路标的观测比例
- 没有被道路边缘的观测比例
- 基于区域的变化概率估计:在上一步中获取了所有遍历数据变化概率的统计数据,用它来更新对该区域的整体变化概率。这个更新是迭代的,每有一个新的遍历数据进行一次更新,每个遍历数据只会使用一次。
工作创建流程 (Job Creator)
工作创建的功能是对上一步的估计结果 $F^*_a(m_l, \tau_l)$ 进行持续监控,在需要的时候触发地图更新流程。触发标准也是通过测试数据和真值学习得到。每次更新工作的创建主要包括将发生变化的区域信息输入至地图更新流程。
地图更新流程 (Map Update)
地图更新流程的功能对所有发生变化的区域创建并集成新的地图块 $m^*_l$ 来最小化环境变化概率。实际应用中,考虑到汽车数据的稀疏性和噪声,只使用单次遍历数据更新地图不太可行,因此作者实现了新的发生利用批量遍历数据来使用学习的方法对地图进行更新。
地图学习 (Map Learner)
地图学习的大致流程为:
- 对指定区域在行进方向使用若干的平面进行分割
- 对轨迹数据中的观测计算和每个平面的交点
- 对每个平面,估计一系列支撑点的位置以及对应的交叉点
- 在每个平面对之间找到对应支撑点对,作者使用杰卡德距离来将两个点集中的点进行匹配,可以进行一对一连接,道路汇合和分开的链接,通过这一步可以获取每条道路边缘的一系列支撑点
- 最后将原始观测数据投影至各自的道路区域中,采用一维的 DBSCAN 来对观测数据进行聚类,最后获取一系列实线和虚线的表示
地图集成 (Map Intergrator)
地图继承流程比较简单,通过将经过修改的区域中的旧版的地图移除,接入新建的地图,并使用一定算法对车道线进行优化使得区域之间的变化足够平滑。
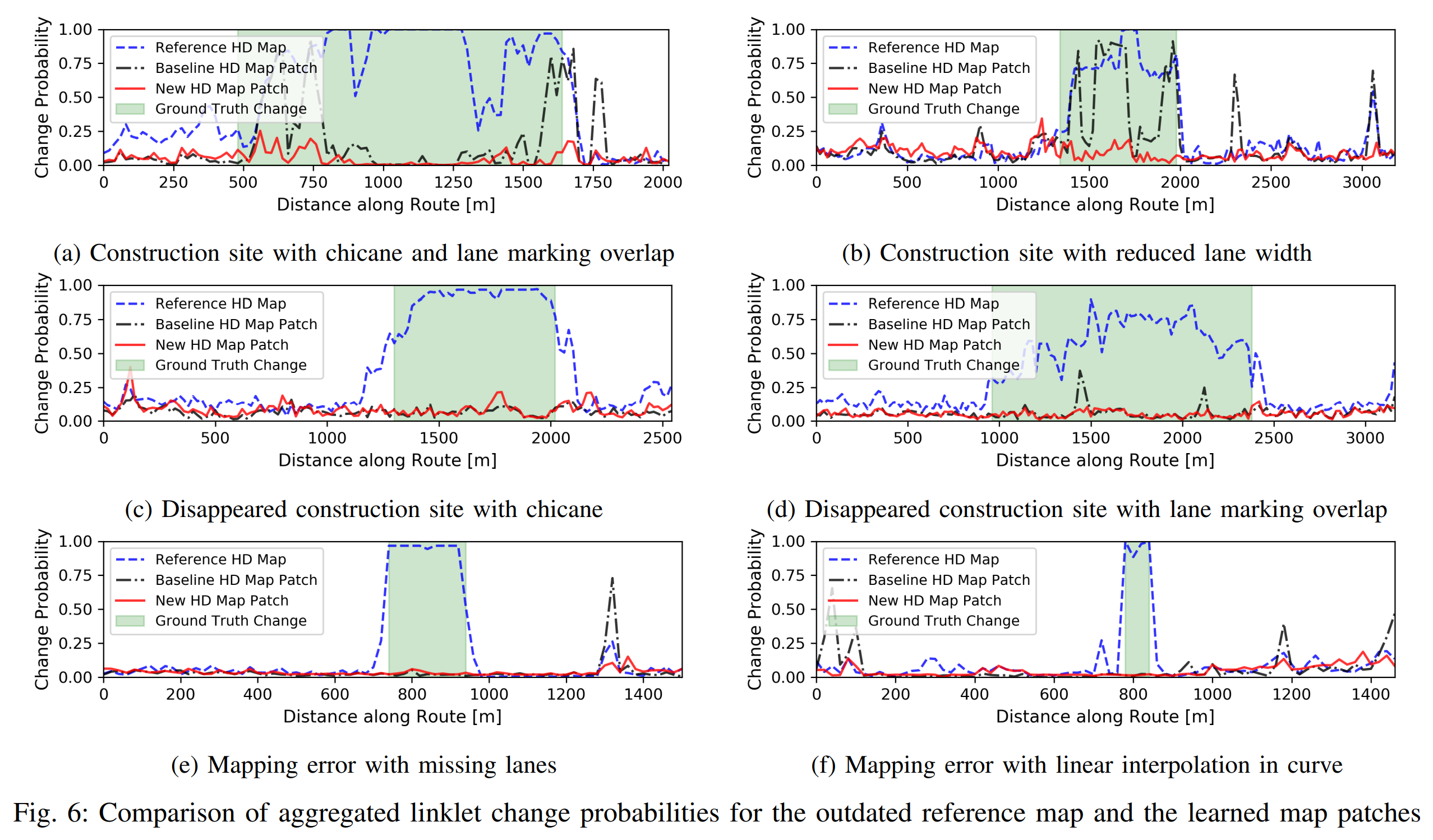
实验结果
作者进行了一系列使用,下图为新旧地图的比较:
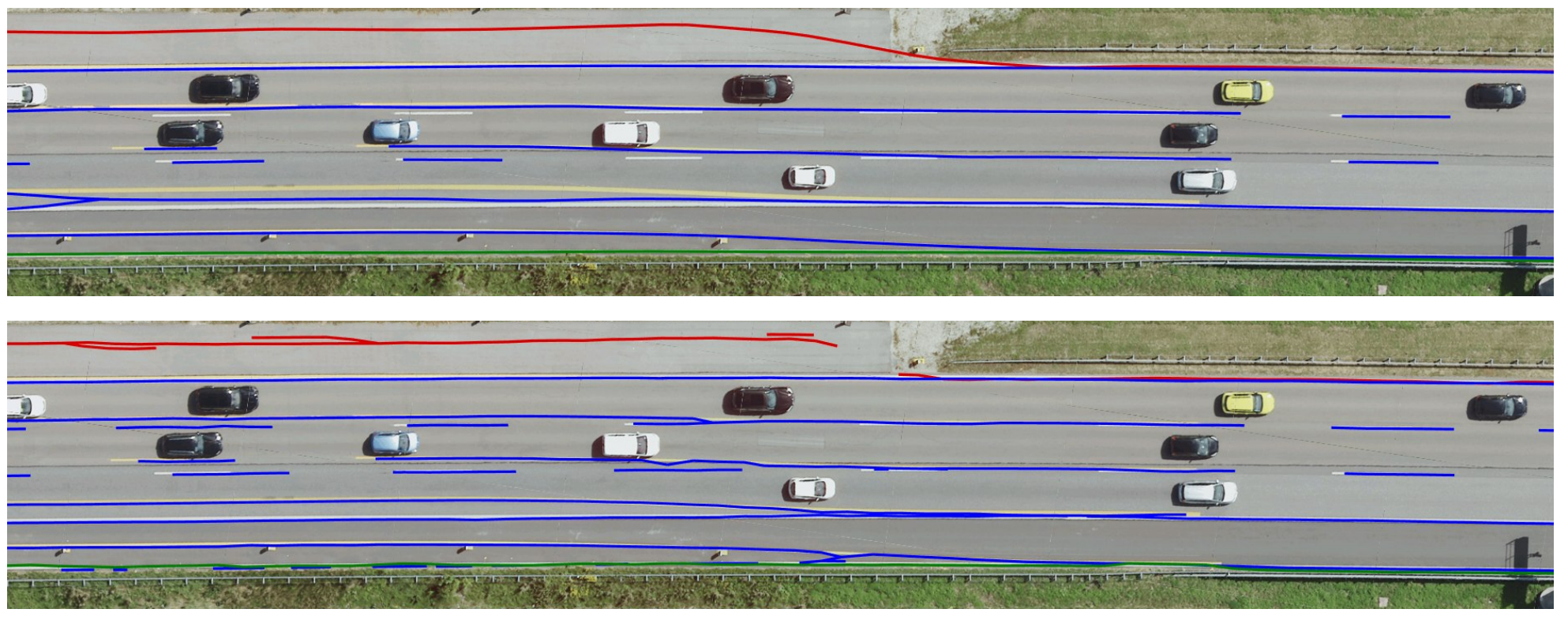
可以看到经过更新后,车道线和环境吻合程度较好。
下面是一系列量化分析,总结了在不同情况下,新旧地图环境变化概率估计以及和真值的比较结果: